微服务拆分那点事【转载】
背景
最近参与了两个项目的开发,两个项目都有多组件,各自服务功能清晰等特点,也就是所谓的微服务,再结合以前的一些单体项目的开发经验,这里主要探讨一下我所理解的微服务和单体项目的优缺点。
我的理解
其实所谓这些服务的拆分与否都是与很多因素有关系,比如:该项目的开发人员数目,该项目的运维敏感度,项目的紧急程度,开发人员的技术熟练程度,微服务架构的基础储备程度等等
因为我们的最终目的是将项目快速完整的实现好,而不是为了显得逼格高而微服务,不是为了人多每人分点活,而故意拆成微服务。总之不能为了微服务而微服务。
比如该项目总工就一个人开发,然后该项目你重启一下服务,对用户接入没啥敏感性,本来就是个没有并发的对内系统,那就完全没必要拆成微服务,就写个单体的,把接入层,数据处理层等通过模块化的代码方式拆开就行了,没必要增加复杂度,加上一些rpc,把一个单体服务拆成四五个微服务,然后增加自己的运维成本和实现成本。
如果该项目是多人协作的,有一定的并发度,对用户接入比较敏感,不能随便重启,并且开发者都对微服务有一定的经验,并且底层rpc,连接池等初始化库都有积累,然后有比较丰富的rpc多服务运维经验,那就可以拆微服务,拆完之后,服务的水平扩展一般是线性的,可以动态的根据流量扩容和缩容。
底层其他非接入层的服务,比如数据处理服务,session服务的重启与上线都不会影响整个项目的接入。同时就提高了该项目的容错性。整体项目的开发进度都能以服务为维度,各自负责一个服务,快速迭代与滚动更新上线。而不像单体应用,一般上线与迭代总是牵一发而动全身。
微服务&单体应用的对比
所以整体从以下几个维度,我来对比一下优缺点
| 微服务 | 单体 | |
|---|---|---|
| 开发人数 | 较多 | 较少 |
| 技术复杂度 | 较高 | 一般 |
| 开发进度 | 分工协作较快,单组件快速迭代 | 一般,互相等待 |
| 功能职责 | 组件拆分明确 | 较模糊 |
| 水平扩展 | 很方便,直接改配置堆机器 | 不支持 |
| 组件重启 | 不影响其他组件 | 牵一发动全身 |
| 运维复杂度 | 较高 | 简单 |
| 适合业务场景 | 高并发,大流量 | 没并发,对内系统居多 |
| 美誉度 | 听着高大上 | 没啥波动 |
怎么拆分
接下来根据一个具体的项目实例,看看如何将一个单体项目,拆分成微服务。
该项目是前两天刚做的一个共享积分项目
项目背景
该项目主要工作两部分,一部分,矿机上报信息给服务端。第二部分:服务端根据矿机上报信息计算分配换算成工作量,然后按工作量百分比分配相应的积分。 同时该项目对接别的用户系统和boss系统等等。
下面是该项目的简单架构图:
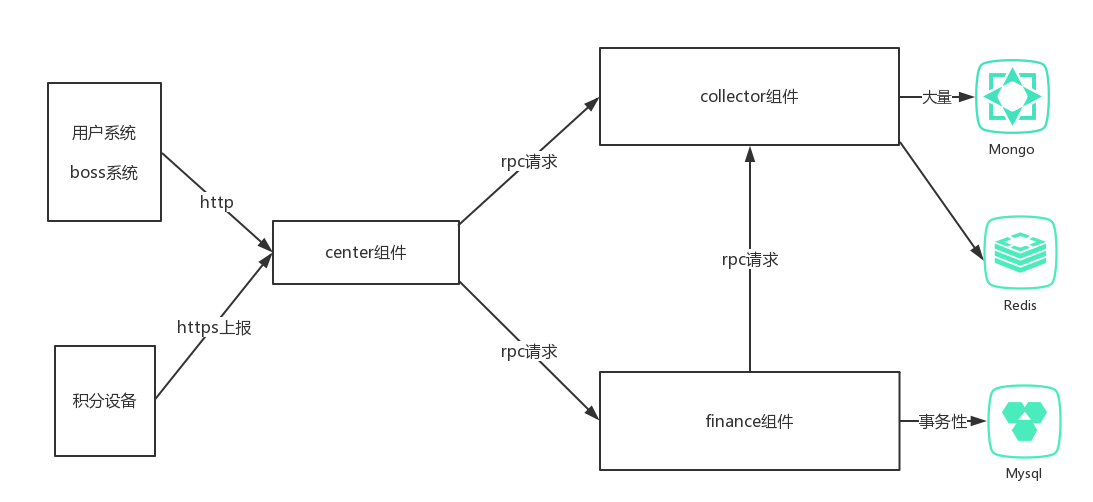
该项目总共三人:三人都参与过微服务的开发,有基础库的储备。 时间比较紧,一周的开发周期。
一开始该项目其实因为复杂度不是太高,其实完全可以做成一个单体应用就行。 比如项目目录: src下, 一个collector目录收集矿机上报,一个finance目录处理一些金融数据。再来一个API目录处理接入请求就行了。外加一些util的公共组件。
然后一个人开发就行了。两周的时间应该能调通。
但是前面也说了,单体应用有诸多的弊端。并且主要还剩两人,你一个人用两周的时间,如果拆成微服务,三人都有相关经验,一个礼拜肯定就可以保质保量的完成相应组件的开发与测试。
因为微服务的每个组件其实都是一个独立的单体应用。组件之间的开发是没有关联的,都是依赖公共库。互相之间的调用都是通过rpc,所以开发是可以并行开发。互不干扰。效率肯定是非常高的。
所以现在我们开始简单将这个单体应用拆成微服务。
第一步:根据服务职责拆分
其实微服务的拆分最根本是一些代码职责的拆分和抽象,这一步和我们模块化的时候思路是一样的。 比如该项目,矿机在不断地上报数据,然后我们通过上报的带宽给分配积分额度。这个其实细分其中的职责,我们可以看到我们需要一个收集上报数据的模块,只负责收集数据,这里抽象了各种数据来源,比如矿机的,比如其他业务接口获取的。都统一到collect模块。这个职责就很明确了。
同时这些数据收集上来以后得集中运算,算完之后得通过内部分配算法,给矿机分配积分额度。这其实是一个类似经济系统的职责,该系统只负责处理金融信息,是个finance经济系统。职责也很明确。
这两个模块对外暴露各种API接口。这个可以抽出来,单独一个接入组件,负责对外统一处理所有的API请求。所以单独起一个center组件。
这个项目相对功能不复杂,所以拆分完,也就三个组件,职责已经比较明确了。
第二步:公共库的初始化
我们把公共的库都放在common里面,这里面包括了log,config,errors等基础库,还有redis,mongo,mysql等db的连接池初始化,还有rpc的连接池初始化,这里或者用grpc或者用户自己基于go自带的rpc的二次封装等。还有trace等用于追踪请求方便日志查询的基本库。
这些基础库是我们做微服务的必备,一般在一个新项目的时候,在前期需求讨论完之后,编码前期,我们会先把这些公共库的初始化工作都做了,比如db的一些连接池初始化不同项目稍微有一些不同。rpc等连接池代码基本都是能复用的。其他的公共库,直接拖到新项目里就能开搞。
第三步:组件之间接口的定义
在初始化完公共库之后,我们先不着急写代码,先把组件之间的接口定义好。这里比如我们三个组件 center,collector,finance三个组件
center是接入层,这里统一处理所有的API请求。http或者https,具体API接口是业务相关。这里不做描述。接入层可以做很轻量的数据处理,不宜过重。不做有状态的数据存储。是一个无状态服务,最终的数据处理通过rpc传给后端相应的组件,基本是一个纯转发的组件。
在配置文件中已经配好了,相应的组件的rpc地址,rpc公共库中我们二次封装了基本的请求逻辑优先级,第一同机器,第二同机房,第三跨机房。
collect和finance组件都对center暴露了grpc pb接口,因为请求从center进来,会通过rpc转到相应组件做单独处理。collect系统和finance系统之间,是单向的数据流动,finance系统需要从collect系统获取数据去统一运算。所以collect系统还需要给finance系统暴露rpc接口。
具体的grpc pb接口有自己的定义语言,比较简单容易上手,在相应的目录下新建proto文件,定义完接口以后,让自动生成pb.go即可,最后代码交互都是走的pb.go里面的结构体。具体的pb编写参考文档即可。
第四步:开始分工写自己的组件了
到此开始编写代码了。每个人都是相对独立的开发,因为接口定义好了,公共库也都已经初始化完毕,然后开发就是完全并行了。编写完之后,自己的组件可以依靠单元测试,做一些基本的测试。然后等联调即可。
总结
以上只是一个相对比较简单的项目拆分。这里也主要说的是一个拆分的思路,和具体实现微服务的时候一些基本工程流程。如果项目比较复杂,可能拆分出来的组件数目就相对较多。本文也主要是聊聊拆分的时候一些我理解的原则,具体实现细节,其实微服务还有很多有意思的地方,比如公共库中一些db的连接池初始化和rpc的连接池初始化,配置的集中管理,动态加载等。单独抽出来都是挺有研究意义的。
本文转载自360 公司 Web 平台部运维开发团队